Generative AI models offer limited transparency into the data that is used to train them and the date ranges of the data used. When using any generative AI tool or interface, always make efforts to carefully assess the accuracy, relevance, and veracity of the generative AI system’s outputs.
Generative models can also perpetuate biases present in their design, build and training data which can be amplified by the prompts input by the user. This has the potential to manifest in harmful ways including but not limited to, perpetuating stereotypes, reinforcing misinformation or creating unequal representation of different groups. When using generative AI, it is essential to be aware of this potential for bias, thoughtfully develop prompts, and critically review and assess the system’s output.
Generative AI does sometimes provide citations/attributions to works it has used in providing its answers but these should be verified using external sources as there are examples of AI models creating “fake” references. Below is an example of a generated citation to an article that does not exist.
Kallajoki M, et al. Homocysteine and bone metabolism. Osteoporos Int. 2002 Oct;13(10):822-7. PMID: 12352394
Below are some examples of different types of bias that might exist in generative AI, and should be taken into consideration when using various tools, or resources that utilize generative AI.
Machine bias refers to the biases that are present in the training data used to build the tools. Generative AI models learn from large human-generated datasets and will ingest the biases present in the text.
Confirmation bias when individuals seek information that confirms their existing beliefs and disregard alternative information. This can be demonstrated either in the training data or in the way that the prompt is written. When users seek information on a particular subject, the AI might selectively generate content that reinforces their viewpoints.
Selection bias when certain groups or perspectives are underrepresented or not present in the training data, the model will not have the information to generate comprehensive answers.
Contextual bias can happen when the model is unable to understand or interpret the context of a conversation or prompt accurately.
Linguistic bias Language models may exhibit preferences for certain dialects or languages, making it challenging for individuals who speak other dialects to access information or engage with AI interfaces.
Automation bias is the propensity for humans to favor suggestions from automated systems such as generative AI and to ignore contradictory information made without automation, even if it is correct.
Review data use policies of the generative AI tool you plan to use. Only input data that are appropriate to share publicly and externally to UNLV. Exercise caution when working with private, sensitive, or identifiable information, and avoid sharing any student information (which could be a FERPA violation), proprietary data, human subject data, controlled/regulated information, third party copyrighted materials or any materials that you do not own or manage the rights to.
Some generative AI tools have data use policies (For example, ChatGPT Enterprise) that may make them HIPAA compliant. Before inputting data into those tools it is recommended that you seek guidance from the Office of Research Integrity.
Uploading a manuscript in whole or in part to a Generative AI tool as part of your review process may breach the requirement to maintain the confidentiality of the content. As an example, NIH recently issued clear guidance prohibiting the use of generative AI in the NIH peer review process.
If you suspect that text or an image has been created using Generative AI, and the author has not disclosed this, you may want to alert the editor of this concern. While there are tools available to detect generated images (see the page of this guide on Detection), note that uploading those images/text during the peer review process may breach the confidentiality of the content.
With lack of transparency on data used in any particular AI model it is unclear if/how authors/creators works are credited/attributed in the model. Additionally there are growing concerns about the unauthorized inclusion of content. When using AI generated content in your research you may be inadvertently including another person's work with incorrect or no citation and attribution, raising issues regarding plagiarism and intellectual property rights.
The challenges brought into the copyright system by generative AI are still being discussed and understood.
The United States Copyright Office has launched an initiative to examine the copyright law and policy issues raised by artificial intelligence (AI) technology, including the scope of copyright in works generated using AI tools and the use of copyrighted materials in AI training. The law is unsettled regarding copyright and generative AI but it is important to be aware that established concepts such as fair use, authorship and derivative works all apply to the creation and use of generative AI content.
For more information on Copyright and Author's Rights, please visit the Copyright and Author Rights guide.
There are tools that attempt to detect the likelihood that an image or text has been generated by an AI tool. Plagiarism checking tools have incorporated detection features to varying degrees of success. Your existing knowledge and skills provide an advantage when reviewing materials within your field of expertise. For materials outside of your field or your comfort zone, fact- and citation-checking skills may be utilized to aid in evaluating these materials, or assessing materials from authors with a wide range of writing styles.
There are also tools for images. For instance, this AI Image Detector allows you to drag and drop an image file. This tool is a proof-of-concept. There may be more robust tools of this type available to you to evaluate published works, or with permission from the creators, unpublished works and student assignments.
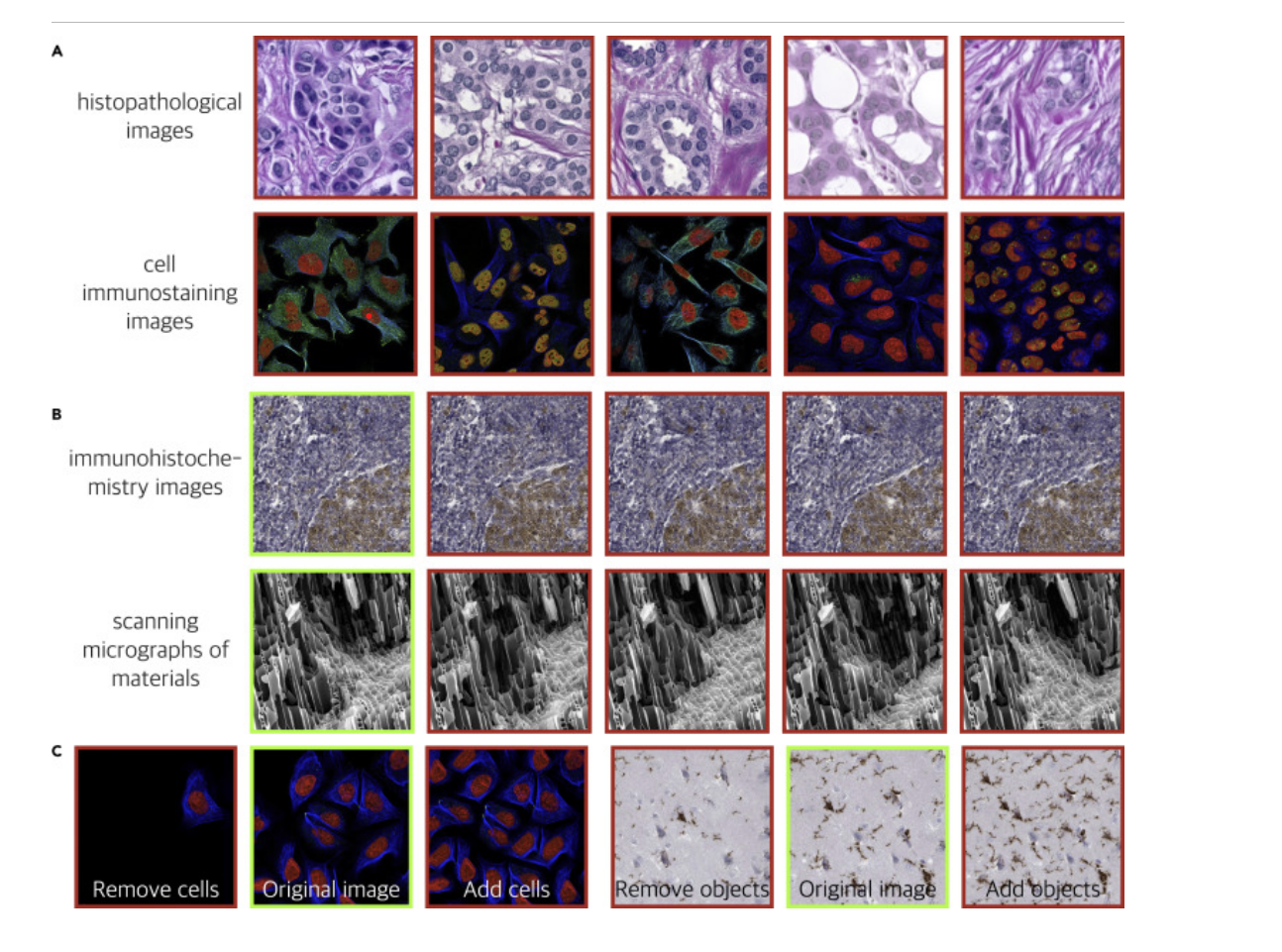
The graphic below (Gu et al., 2022) shows AI generated images to highlight how challenging it is to detect them without tools.
The first image on each row is the original image. For the first two sections, the last four images are regenerated from the first real image. Section A in the graphic below are all fake images generated from a well trained generative AI model. Section B is the result of regenerating images using a generative model trained on a single image. Section C shows the results of using generative AI to manipulate images. The generative models manipulate images by directly generating images that are similar in features but with modified content. For each group, the images in the middle are the original images, and the images on both sides are deliberately manipulated fake images.
While generative AI offers promising capabilities for researchers across disciplines, understanding its nuances like perplexity and burstiness is crucial. These concepts act as tools to evaluate the AI's outputs, ensuring they are insightful, relevant, and unbiased. By being aware of these metrics, scholars can better navigate and leverage the vast potentials of generative AI in their research endeavors.
In addition, understanding these concepts could help scholars identify whether a text is AI-generated or not. While neither perplexity nor burstiness is a foolproof method to identify AI-generated content on its own, they provide valuable tools for discerning readers.
Observing for unexpected combinations of information or repetitive emphasis can offer hints toward the origin of the text. In an era of sophisticated AI, critical reading combined with an awareness of these concepts becomes more important than ever.
What is it? Perplexity is a measure used to evaluate how well a probability distribution predicts a sample. In the context of generative AI, it quantifies how "surprised" the model is by a given input, based on the data it has been trained on. A lower perplexity indicates that the model is less surprised and thus better at predicting the input.
How does it relate to AI-generated content? If an AI language model produces a piece of text that seems improbable or unexpected based on its training, the perplexity would be high. For instance, a coherent and grammatically correct text would typically have lower perplexity than a jumbled, nonsensical one.
Why is it important? Imagine you're reading a book and trying to guess the next word in a sentence. If the language and context are familiar, you can often make accurate predictions. Similarly, a language model trained on vast amounts of data uses perplexity to assess how accurately it can predict or understand the next word or piece of data
For researchers, understanding perplexity helps in:
Considerations for Researchers:
High Perplexity (Unexpected and Hard to Predict)
Low Perplexity (Expected and Easy to Predict)
Identifying AI-generated Content:
Example of High Perplexity (Possible AI Error)
Example of Low Perplexity (AI Imitating Human-Like Output)
What is it? Burstiness refers to the tendency of certain events or terms to appear in clusters rather than uniformly or randomly distributed. In the context of AI-generated content, it can manifest as repetitive or clustered outputs when you might expect more diverse responses.
Why is it important? Understanding burstiness is essential because it provides insight into:
For researchers, grasping the concept of burstiness can aid in:
Detecting anomalies or repetitive patterns in AI-generated outputs.
Considerations for Researchers:
Burstiness Illustrative Examples
High Burstiness (Repetitive and Clustered)
Low Burstiness (Diverse and Spread Out)
Identifying AI-generated content:
Example of High Burstiness (Possible AI Overemphasis)
Example of Low Burstiness (AI Imitating Diverse Human-Like Output)
When using generative AI tools in writing, acknowledge and cite the output of those tools in your work. Norms and conventions for citing AI-generated content are likely to evolve over the next few years but the below guides provide information on current guidelines from the major style guides.
In the past few years there have been increasing instances of the systematic manipulation of the publishing process. Fraudulent manuscripts that resemble legitimate research articles have made their way through the peer review process and have been published in reputable journals. “Paper Mills”, organizations that produce and sell fraudulent manuscripts are at the center of this problem. This Nature news article describes how more than 10,000 research articles have been retracted in 2023 due to integrity issues and the systematic manipulation of the publishing process.
The impact of fraudulent research being published with the stamp of authority of a peer-reviewed journal is far-reaching. Not only is it damaging to the trust researchers place in the publication system, but the fraudulent research may be used to build more research, wasting money and time for a researcher. Scholarly journals have become increasingly aware of paper mill articles and are working to develop methods to screen for them. For researchers, it is extremely difficult to detect these published articles. While this issue is not directly the result of AI. AI is exacerbating the problem making it easier to fabricate research, and the methods described in this guide for detecting AI may be useful in detecting fabricated research. Additionally researchers should become familiar with how retractions are communicated in their discipline and journals. This can help to avoid citing fraudulent research, but of course this only applies to research that has been identified as fraudulent. The Retraction Watch database is a tool that can be used to identify retracted journal articles.